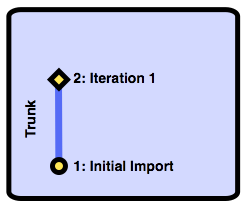
In Bazaar for Agile Teams, we completed an iteration, and our trunk branch's history looks like this:
A name associated with a revision.
Now that we have a completed iteration and a handful of features, we're going to release it to our customers. It would be helpful if we could remember that our first release was revision 2. Bazaar lets you assign arbitrary names to revisions called tags. To assign a name to revision 2, we use the bzr tag command:
Tag a revision with a name.
trunk fmccann$ bzr tag -r2 release-1
Created tag release-1.
trunk fmccann$ bzr log -r release-1
------------------------------------------------------------
revno: 2 [merge]
tags: release-1
committer: Charlie Harvey <charlie@bzrinit.com>
branch nick: trunk
timestamp: Sun 2015-12-22 20:27:59 -0500
message:
Iteration 1
We've tagged revision 2 as "release-1". As you can see in the call to bzr log, we can use a tag in place of a revision number in Bazaar commands. Also, you can see that the tag now shows up as part of the log for revision 2. Tagging is very useful to mark which revision of a project was released, but you can attach any meaningful names you'd like to any revision.
You can use the bzr tags command to see a complete list of tags:
trunk fmccann$ bzr tags
release-1 2
trunk fmccann$ bzr tags --show-id
release-1 charlie@bzrinit.com-20131223012759-dwtcg6cehlbqc128
Remember that every revision has a unique revision identifier that can be used to identify revisions across branches. When we add a tag to a revision, we're really tagging the unique identifier.
As the team keeps working, they're going to land more revisions in the trunk.
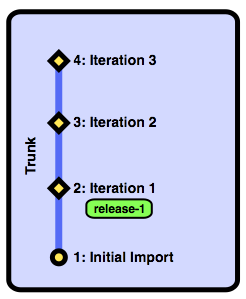
This approach is fine for ongoing development, but what if there's a bug in the released version of the product? We could just wait until the next planned release, but it would be better to fix the released version immediately. To accomplish this, we need more than just a tag, we need a release branch.
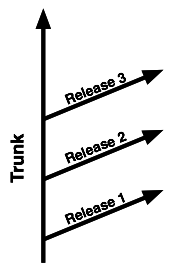
One way to model this is to always do forward development in the trunk branch, and fork off release branches. Depending on your project you might have to maintain multiple release branches or maintain a single "stable" branch which represents the current release.
If we had to fix a critical problem the released version of our sample project, we'd create a new brach from revision release-1 with the command bzr branch -r release-1 stable. Then we'd have the following two branches:
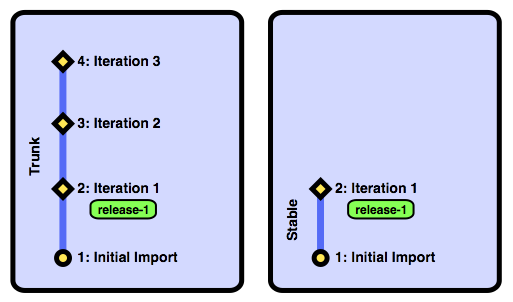
Now we have a stable branch that reflects what's been released. We can fix critical bugs in this branch and release the fixed code to customers without waiting for development to catch up. Let's see what this looks like after we fix two critical bugs and release again.
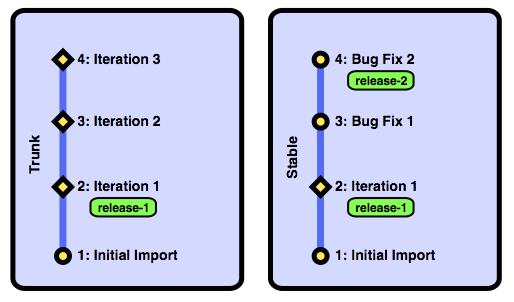
We've fixed the critical bugs in the stable branch and we now have a new tag showing which revision shipped. While this is great for the customers, we have a new problem— the fixes aren't in the trunk! That means that people who are working off of trunk aren't building their new revisions on top of the fixes, and the next time we release from the trunk branch, we'll lose the fixes. The answer to this problem is to merge changes from the stable branch into the trunk branch. After committing the merge, this is what trunk looks like:
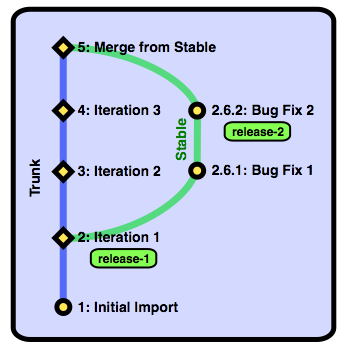
The fixes have been incorporated into the trunk branch, so everyone working from trunk will get them. The next time we release from trunk, the fixes will be there. And you can see how the tag "release-2" can still retrieve the state of the code from the second release.
Fixing a bug in the branch where it occured then merging back into your trunk is called a Daggy Fix.
Just as we used branches to model iterations and user stories, we can also use branches to model stable and development lines of code. Other uses for branches could be:
- Team branches such as our iteration branch from Bazaar for Agile Teams or even department wide branches.
- Instead of merging work directly into a trunk or an iteration branch, we could first send revisions to a QA branch to be reviewed and approved.
- Experimental or "spike" branches such as the experimental branch we used to explore cake recipes in Branching Zen.
Bazaar is flexible enough to manage a handful of branches needed by a single team and to handle the larger picture in an organization that might have multiple teams:
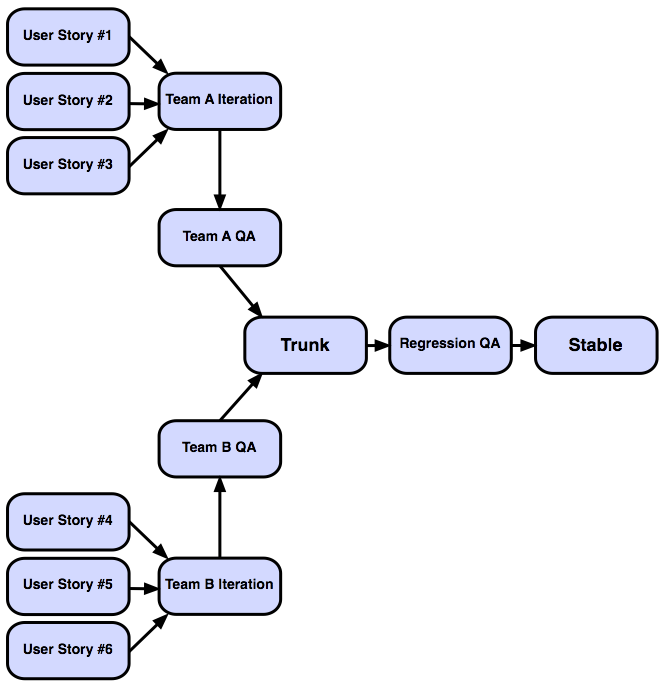
You can use as many or as few branches as needed to model your development pipeline.
Working with Gatekeepers
When working alone, in informal groups, or on agile teams, developers usually have commit rights to the team's shared branch. However, in larger organizations or on projects where there are a lot of people submitting patches and a handful of project maintainers, you might want to use gatekeepers.
A nominated person or piece of software that has write access to a key branch.
In this scenario, developers might only have read access to a branch, and a nominated developer, the gatekeeper, would have write access. In the pipeline example above, perhaps all the developers on Team A have write access to the Team A Iteration branch, but not to the Team A QA branch. In that scenario, only a trusted developer would be able to promote revisions to the QA branch.
The simplest way of implementing a gatekeeper process is to allow developers to mirror personal branches to a server, then the gatekeeper could merge their work into an upstream branch.
In some cases, developers might not have any write access at all, even to push copies of their work to a remote mirror where a gatekeeper could inspect it.
Creates a merge directive that can be sent to a gatekeeper.
In this case, developers could use the bzr send command to generate a merge directive file with all their changes and mail it to a project's gatekeeper. A merge directive is sort of like a patch file except that it contains historical information instead of just the latest changes.
In Branching Zen, we were collaborating with Charlie on a cake recipe. Let's say Charlie only had read access to our recipe branch and he wanted to make two more changes:
charlie charvey$ bzr missing
Using saved parent location: bzr+ssh://dev.example.com/srv/recipe
You have 2 extra revisions:
------------------------------------------------------------
revno: 6
committer: Charlie Harvey <charlie@bzrinit.com>
branch nick: charlie
timestamp: Mon 2015-12-23 15:29:01 -0500
message:
added more cocoa to the cake
------------------------------------------------------------
revno: 5
committer: Charlie Harvey <charlie@bzrinit.com>
branch nick: charlie
timestamp: Mon 2015-12-23 15:28:35 -0500
message:
added more espresso powder to the frosting
Since he doesn't have write access to the recipe repository, he can call bzr send to email us a merge-directive.
charlie charvey$ bzr send
Using saved parent location "bzr+ssh://dev.example.com/srv/recipe" to determine what
changes to submit.
Bundling 2 revisions.
[MERGE] added more cocoa to the cake
To: Fred McCann <fred@bzrinit.com>
From: Charlie Harvey <charlie@bzrinit.com>
Subject: [MERGE] added more cocoa to the cake
I added more cocoa and more espresso.
Bam.
- Charlie

When we get Charlie's email, we'll apply his merge directive file to our branch with bzr merge:
recipe fmccann$ bzr merge /tmp/charlie-6.patch
M cake.txt
All changes applied successfully.
recipe fmccann$ bzr commit -m"Merged Charlie's patch"
Committing to: /home/fmccann/recipe/
modified cake.txt
Committed revision 5.
recipe fmccann$ bzr log -n0
------------------------------------------------------------
revno: 5 [merge]
committer: Fred McCann <fred@bzrinit.com>
branch nick: recipe
timestamp: Mon 2015-12-23 15:48:28 -0500
message:
Merged Charlie's patch
------------------------------------------------------------
revno: 4.1.2
committer: Charlie Harvey <charlie@bzrinit.com>
branch nick: charlie
timestamp: Mon 2015-12-23 15:29:01 -0500
message:
added more cocoa to the cake
------------------------------------------------------------
revno: 4.1.1
committer: Charlie Harvey <charlie@bzrinit.com>
branch nick: charlie
timestamp: Mon 2015-12-23 15:28:35 -0500
message:
added more espresso powder to the frosting
...
One last option with the gatekeeper approach is to use an automated system rather than a human being to serve as the gatekeeper. Since we can use bzr send to generate merge directives, it's easy enough to make a process that will apply these changes for us. For more information on this approach, see Bazaar's documentation on gatekeepers and check out Patch Queue Manager, which is an automated gatekeeper for Bazaar.
Review
You can use Bazaar to manage your entire development pipeline regardless of how simple or sophisticated it may be. In this part of the tutorial we learned how to:
- Tag revisions.
- Manage trunk and stable branches and deal with fixing bugs in production.
- How to think about the entire development pipeline and how to model it with branches.
- How to work with gatekeepers.
- How to send merge directives with bzr send.